I’m taking Berkeley’s CS294 𝙇𝙇𝙈 𝘼𝙜𝙚𝙣𝙩𝙨 course, and I particularly enjoyed a recent lecture from Burak Gokturk where he explained several approaches that will help enterprises get significantly better results from foundation models.
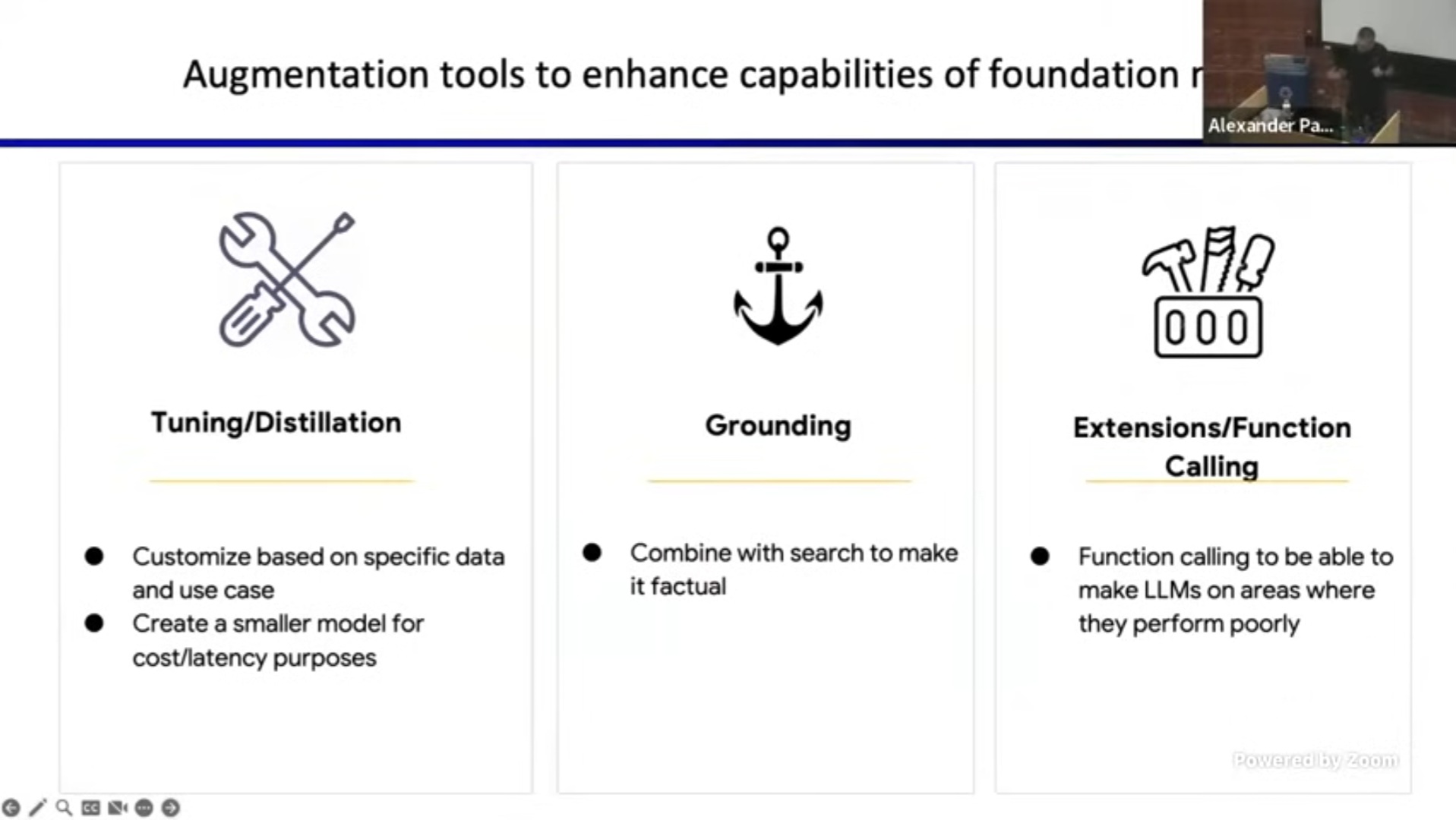
🔧 𝗧𝘂𝗻𝗶𝗻𝗴/𝗗𝗶𝘀𝘁𝗶𝗹𝗹𝗮𝘁𝗶𝗼𝗻
• Tuning is customizing a model based on specific data and/or use case
This ranges from techniques as basic as prompt design (providing few shot examples as part of your prompt), to actual retraining of the model (either full [very costly] retraining, or more efficiently with a concept like “LoRA”).
• Distillation is creating a smaller model for improved cost/latency, using a teacher/student pattern, where your foundation model will “teach” (generate training data and reward/penalise) a smaller (student) model.
Not every use case needs a model that can “answer all the questions in the world”. Often, a smaller, specialized model is more effective.
⚓ 𝗚𝗿𝗼𝘂𝗻𝗱𝗶𝗻𝗴
• Combine with search to make it factual (also known as “RAG”, Retrieval Augmented Generation)
• Can be applied to web data or enterprise data
Think of this as making LLMs more reliable by connecting them to verified information sources (for example post training cutoff date), or sources that matter to your context (your enterprise data).
🛠️ 𝗘𝘅𝘁𝗲𝗻𝘀𝗶𝗼𝗻𝘀/𝗙𝘂𝗻𝗰𝘁𝗶𝗼𝗻 𝗖𝗮𝗹𝗹𝗶𝗻𝗴
Like the “Phone a Friend” option in “Who Wants to Be a Millionaire,” this involves 2 main complexities:
• Recognizing when the model needs external help
• Selecting the right tool for the task
For example, a LLM can’t book flights directly, but through function calling, it could use an Expedia extension to complete this task.
As a fractional CDO, I love exploring how these concepts can address real business challenges in real world AI implementations.
If you’re interested in the course, you can check it out here.